100 changed files with 352 additions and 303 deletions
BIN
.RData
+ 80
- 76
Deep Learning in R.Rmd
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
File diff suppressed because it is too large
+ 61
- 223
Deep_Learning_in_R.html
+ 17
- 0
Deep_Learning_in_R_cache/html/__packages
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
Deep_Learning_in_R_cache/html/require(keras)_4a95b8774714cd7667d4bbf8d95ef0d4.RData
BIN
Deep_Learning_in_R_cache/html/require(keras)_4a95b8774714cd7667d4bbf8d95ef0d4.rdb
BIN
Deep_Learning_in_R_cache/html/require(keras)_4a95b8774714cd7667d4bbf8d95ef0d4.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-10_bb765d51318b911df473bfe27f9399a1.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-10_bb765d51318b911df473bfe27f9399a1.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-10_bb765d51318b911df473bfe27f9399a1.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-11_9bce284609cda3286ada25ec8cf29fe2.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-11_9bce284609cda3286ada25ec8cf29fe2.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-11_9bce284609cda3286ada25ec8cf29fe2.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-12_3821e394b95e072f935068414f88dd3e.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-12_3821e394b95e072f935068414f88dd3e.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-12_3821e394b95e072f935068414f88dd3e.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-13_1695239dde76f9f0869e351aae020883.RData
+ 0
- 0
Deep_Learning_in_R_cache/html/unnamed-chunk-13_1695239dde76f9f0869e351aae020883.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-13_1695239dde76f9f0869e351aae020883.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-14_fb13f2d336cd6cc0d5c30b9c4c1a4583.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-14_fb13f2d336cd6cc0d5c30b9c4c1a4583.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-14_fb13f2d336cd6cc0d5c30b9c4c1a4583.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-15_2802a50d8885003f9037f8c13e229397.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-15_2802a50d8885003f9037f8c13e229397.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-15_2802a50d8885003f9037f8c13e229397.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-16_e93bbac295d347948c437f6b8be85f59.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-16_e93bbac295d347948c437f6b8be85f59.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-16_e93bbac295d347948c437f6b8be85f59.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-17_fef6216cc3763052cf9c80149cfe7cc2.RData
+ 0
- 0
Deep_Learning_in_R_cache/html/unnamed-chunk-17_fef6216cc3763052cf9c80149cfe7cc2.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-17_fef6216cc3763052cf9c80149cfe7cc2.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-18_05ecc2868a72c07b0d5b8bc950b80d5d.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-18_05ecc2868a72c07b0d5b8bc950b80d5d.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-18_05ecc2868a72c07b0d5b8bc950b80d5d.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-19_b0e0fbe91d2b2969c3eee6f0aa64b6b7.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-19_b0e0fbe91d2b2969c3eee6f0aa64b6b7.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-19_b0e0fbe91d2b2969c3eee6f0aa64b6b7.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-20_f835d053d08f2c7ca2355b9bf5c78dca.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-20_f835d053d08f2c7ca2355b9bf5c78dca.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-20_f835d053d08f2c7ca2355b9bf5c78dca.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-21_8ca6fc5509dd2e438532bf7d3bace749.RData
+ 0
- 0
Deep_Learning_in_R_cache/html/unnamed-chunk-21_8ca6fc5509dd2e438532bf7d3bace749.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-21_8ca6fc5509dd2e438532bf7d3bace749.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-22_4d460e32dfe62e168283a1af95c38062.RData
+ 0
- 0
Deep_Learning_in_R_cache/html/unnamed-chunk-22_4d460e32dfe62e168283a1af95c38062.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-22_4d460e32dfe62e168283a1af95c38062.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-23_60c1a55fc84dc0dea24e0f4b711ee9e1.RData
+ 0
- 0
Deep_Learning_in_R_cache/html/unnamed-chunk-23_60c1a55fc84dc0dea24e0f4b711ee9e1.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-23_60c1a55fc84dc0dea24e0f4b711ee9e1.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-24_e0e68bc65e8be667289586ce24d9b2ff.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-24_e0e68bc65e8be667289586ce24d9b2ff.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-24_e0e68bc65e8be667289586ce24d9b2ff.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-25_55397e14a6ace60c79497409784306ca.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-25_55397e14a6ace60c79497409784306ca.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-25_55397e14a6ace60c79497409784306ca.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-26_093e583b095fe17ad0da67e72e154d27.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-26_093e583b095fe17ad0da67e72e154d27.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-26_093e583b095fe17ad0da67e72e154d27.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-27_5810f71bc44e68595d7bc2f162913ea4.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-27_5810f71bc44e68595d7bc2f162913ea4.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-27_5810f71bc44e68595d7bc2f162913ea4.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-28_375ad401cb5a8df0dfe4815fbbfc4692.RData
+ 0
- 0
Deep_Learning_in_R_cache/html/unnamed-chunk-28_375ad401cb5a8df0dfe4815fbbfc4692.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-28_375ad401cb5a8df0dfe4815fbbfc4692.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-29_9cd5192000319d370709958867a3892d.RData
+ 0
- 0
Deep_Learning_in_R_cache/html/unnamed-chunk-29_9cd5192000319d370709958867a3892d.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-29_9cd5192000319d370709958867a3892d.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-30_e73310f60fb9dd40c6b7e5fcedd76464.RData
+ 0
- 0
Deep_Learning_in_R_cache/html/unnamed-chunk-30_e73310f60fb9dd40c6b7e5fcedd76464.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-30_e73310f60fb9dd40c6b7e5fcedd76464.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-31_32c2f9b4b33a2fd3c1be561f6a1ee593.RData
+ 0
- 0
Deep_Learning_in_R_cache/html/unnamed-chunk-31_32c2f9b4b33a2fd3c1be561f6a1ee593.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-31_32c2f9b4b33a2fd3c1be561f6a1ee593.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-32_440f1003e124cde39388d86af9f2524d.RData
+ 0
- 0
Deep_Learning_in_R_cache/html/unnamed-chunk-32_440f1003e124cde39388d86af9f2524d.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-32_440f1003e124cde39388d86af9f2524d.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-3_0e9b76ed9c5f2d49811a44b951fdecb1.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-3_0e9b76ed9c5f2d49811a44b951fdecb1.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-3_0e9b76ed9c5f2d49811a44b951fdecb1.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-4_6a8f92a2a39c40f5fc18dd3b917a541a.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-4_6a8f92a2a39c40f5fc18dd3b917a541a.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-4_6a8f92a2a39c40f5fc18dd3b917a541a.rdx
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-5_570a7c2f944a761a305df3dcef4571da.RData
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-5_570a7c2f944a761a305df3dcef4571da.rdb
BIN
Deep_Learning_in_R_cache/html/unnamed-chunk-5_570a7c2f944a761a305df3dcef4571da.rdx
File diff suppressed because it is too large
+ 14
- 0
Deep_Learning_in_R_files/figure-html/unnamed-chunk-10-1.svg
+ 1
- 1
Deep_Learning_in_R_files/figure-html/unnamed-chunk-13-1.svg
{kind=link}
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
File diff suppressed because it is too large
+ 38
- 0
Deep_Learning_in_R_files/figure-html/unnamed-chunk-14-1.svg
File diff suppressed because it is too large
+ 38
- 0
Deep_Learning_in_R_files/figure-html/unnamed-chunk-16-1.svg
BIN
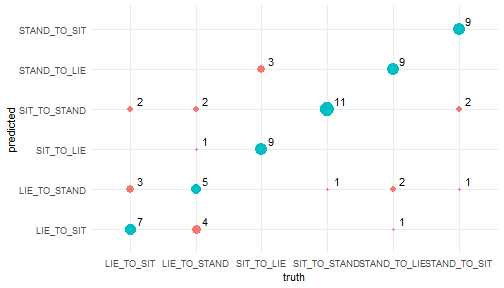
Deep_Learning_in_R_files/figure-html/unnamed-chunk-17-1.png
{kind=link}
File diff suppressed because it is too large
+ 26
- 0
Deep_Learning_in_R_files/figure-html/unnamed-chunk-17-1.svg
File diff suppressed because it is too large
+ 26
- 0
Deep_Learning_in_R_files/figure-html/unnamed-chunk-18-1.svg
File diff suppressed because it is too large
+ 26
- 0
Deep_Learning_in_R_files/figure-html/unnamed-chunk-20-1.svg
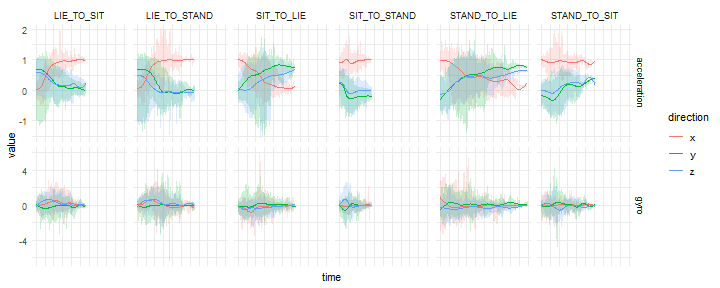
BIN
Deep_Learning_in_R_files/figure-html/unnamed-chunk-28-1.png
{kind=link}
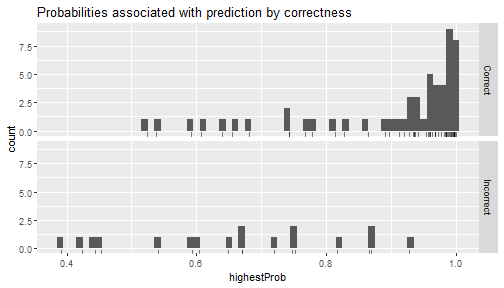
BIN
Deep_Learning_in_R_files/figure-html/unnamed-chunk-29-1.png
{kind=link}
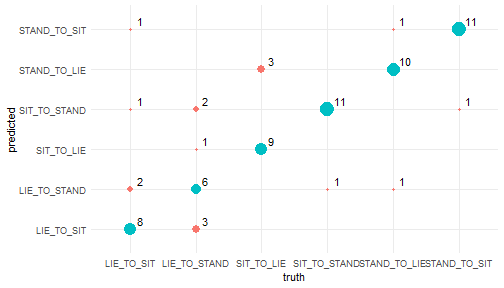
BIN
Deep_Learning_in_R_files/figure-html/unnamed-chunk-30-1.png
{kind=link}
BIN
Deep_Learning_in_R_files/figure-html/unnamed-chunk-31-1.png
{kind=link}
BIN
Deep_Learning_in_R_files/figure-html/unnamed-chunk-32-1.png
{kind=link}